Spark/Hive
创始人
2024-05-30 15:05:59
0次
Spark/Hive
- Hive 原理
- Spark with Hive
- SparkSession + Hive Metastore
- spark-sql CLI + Hive Metastore
- Beeline + Spark Thrift Server
- Hive on Spark
- Hive 擅长元数据管理
- Spark 擅长高效的分布式计算
Spark + Hive 集成 :
- Hive on Spark : Hive 用 Spark 作为底层的计算引擎时
- Spark with Hive : Spark 把 Hive 当元信息的管理工具
Hive 原理
Hive架构 , 可插拔的第 三方独立组件 :
- User Interface 提供 SQL 接入服务
- CLI 与 Web Interface 在本地接收 SQL 查询语句
- Hive Server 2 提供 JDBC/ODBC 客户端连接,从远程提交 SQL 查询请求
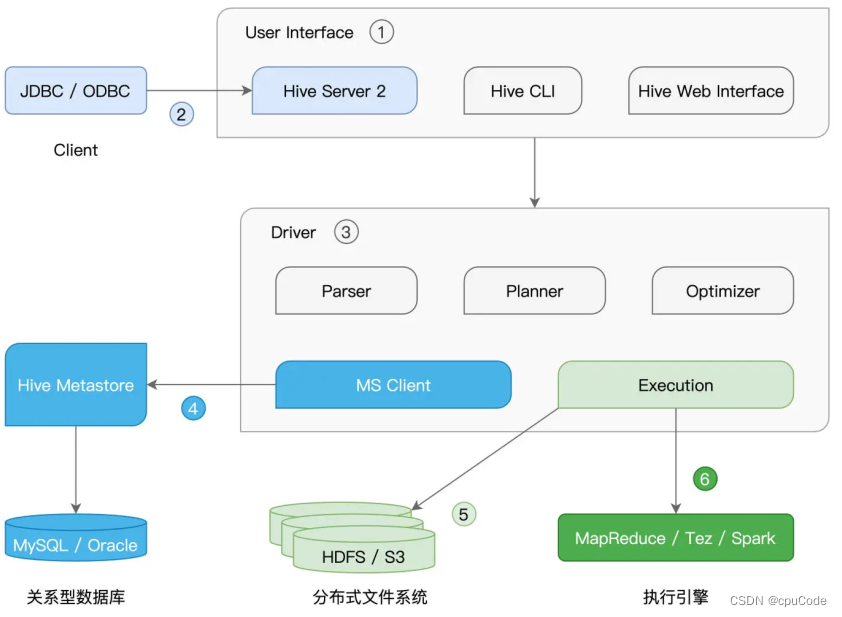
SQL 查询的工作过程 :
- 收到 SQL 后,Driver 先用 Parser ,将查询语句转化为 AST(Abstract Syntax Tree,查询语法树)
- Hive 从 Hive Metastore 拿表的元信息,如 : 表名、列名、字段类型、数据文件存储路径、文件格式
- Planner 根据 AST 生成执行计划
- Optimizer 优化执行计划
- Execution 提交执行计划
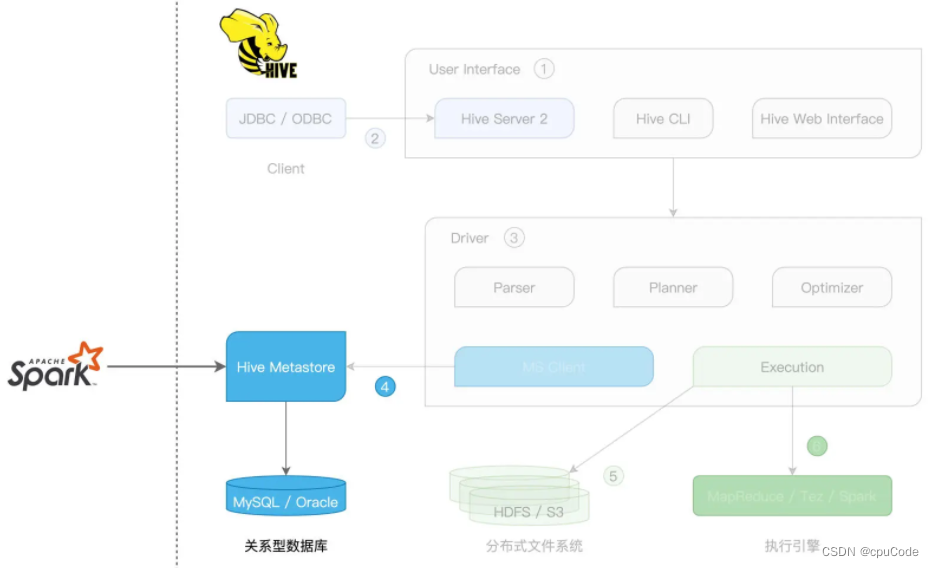
Spark with Hive
Spark with Hive 集成方式 :
- 创建 SparkSession,访问 Hive Metastore
- 通过 spark-sql CLI,访问本地 Hive Metastore
- 通过 Beeline,访问 Spark Thrift Server
SparkSession + Hive Metastore
启动 Hive Metastore
hive --service metastore
Spark 拿 Metastore 访问地址的两种办法 :
- 创建 SparkSession 时,通过 config 指定
hive.metastore.uris - 把Hive的
hive-site.xml拷到 Spark 的 conf 下
spark-shell 下写代码 :
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrameval hiveHost: String = _// 创建SparkSession实例
val spark = SparkSession.builder().config("hive.metastore.uris", s"thrift://hiveHost:9083").enableHiveSupport().getOrCreate()// 读取Hive表,创建DataFrame
val df: DataFrame = spark.sql(“select * from salaries”)
df.show/** 结果打印
+---+------+
| id|salary|
+---+------+
| 1| 26000|
| 2| 30000|
| 4| 25000|
| 3| 20000|
+---+------+
*/
SparkSession + Hive Metastore 集成方式 :
- Spark 只涉及 Hive 的 Metastore
spark-sql CLI + Hive Metastore
spark-sql CLI 与 Hive Metastore 要在同个节点
- spark-sql CLI 只能访问 本地 Hive Metastore
Beeline + Spark Thrift Server
用 Beeline 客户端,连接 Spark Thrift Server,从而完成 Hive 表的访问与处理
Hive Server 2 (Hive Thrift Server 2) 采用 Thrift RPC 协议框架
Beeline + Spark Thrift Server 集成 :
- Spark Thrift Server 与 Hive Server 2 的实现逻辑一样。最大区别:SQL 查询接入后的解析、规划、优化与执行

启动 Spark Thrift Server :
$SPARK_HOME/sbin/start-thriftserver.sh
Spark Thrift Server 启动后,在任意节点上通过 Beeline 就能访问该服务
beeline -u "jdbc:hive2://hostname:10000"
Hive on Spark
Hive on Spark :Hive 用 Spark 作为分布式执行引擎
- SQL 语句的解析、规划与优化都由 Hive 的 Driver 完成
- Hive on Spark 衔接的部分是 Spark Core
指定 Spark 执行引擎
set hive.execution.engine=spark
上一篇:NTLM协议原理分析
下一篇:Spring-Retry失败重试
相关内容
热门资讯
精选情感电台广播稿
本站为大家精选了精选情感电台广播稿,欢迎阅读。 精选情感电台广播稿【一】 大家好,收音机旁我...
致接力运动员加油稿
致接力运动员加油稿(一) 小小接力棒,连着你和我,牵着你的情,动着我的心。这是团结的象征,这是...
致敬最美逆行者讲话稿
致敬最美逆行者讲话稿范文(精选11篇) 随着社会一步步向前发展,各种讲话稿频频出现,讲话稿可以按照...
《观潮》说课稿
《观潮》说课稿15篇 作为一位杰出的教职工,总不可避免地需要编写说课稿,说课稿有助于提高教师的语言...
八年级下册《马说》说课稿
八年级下册《马说》说课稿八年级下册《马说》说课稿1 一.说教材 1. 教材所处的地位和作用: ...
小学数学说课例稿
实际上数学就在学生身边,教师要善于引导学生运用数学的眼光去观察和认识现实生活中的客观事物,在有关...
《放小鸟》说课稿
《放小鸟》说课稿 作为一名为他人授业解惑的教育工作者,时常需要用到说课稿,借助说课稿可以更好地提高...
《平行四边形的认识》数学说课...
《平行四边形的认识》数学说课稿 作为一位兢兢业业的人民教师,时常要开展说课稿准备工作,借助说课稿可...
职工拾金不昧新闻稿
职工拾金不昧新闻稿 拾金不昧拾到东西并不隐瞒下来据为己有,指良好的人的道德和社会风尚。以下是小编为...
《鸬鹚》优秀说课稿
《鸬鹚》优秀说课稿 《鸬鹚》是义务教育六年制小学语文第七册第21课,作者是我国现代著名的文学家郑振...
校园红领巾广播稿
校园红领巾广播稿100字(通用27篇) 有在广播站锻炼的同学们,广播前一般都会提前做好广播稿,优秀...
《最后一课》说课稿
《最后一课》说课稿《最后一课》说课稿1 它是初中一年级的教学内容,具体编排在第一册第二单元的第二篇...
国庆节朗诵稿
国庆节朗诵稿 在我们上学期间,大家对朗诵稿都再熟悉不过了吧,朗诵是口语交际的一种重要形式。你知道什...
运动会广播稿100字:致短跑...
1.间的成败 ——致百米运动员 红色的跑道,承载着多少汗水,一条红线,记载着多少成败。 一次...
万能开会发言稿
万能开会发言稿公司开会,肯定是需要提前做好准备的,也要准备好要说的话,或是发言稿,万能开会发言稿。万...
《要下雨了》说课稿
小学语文一年级下册《要下雨了》说课稿范文 作为一名老师,时常需要编写说课稿,说课稿有助于学生理解并...
运动会加油稿
运动会加油稿20字 导语:运动会少不了加油,简单的一句话,可以给予运动会无限的力量。下面是为大家的...
小学语文《数字歌》说课稿
小学语文《数字歌》说课稿 【说教材】 我说的是九年义务教育新课程北师大版语文一年级上册第三单元《...
高三百日誓师领导发言稿
高三百日誓师领导发言稿 在不断进步的时代,发言稿使用的情况越来越多,发言稿可以帮助发言者更好的表达...
小学经典美文朗诵稿
通过朗诵可以陶冶性情,开阔胸怀,文明言行,增强理解。下面是大学网小编为大家整理了小学经典美文朗诵稿,...