数仓管理工具之Hive的崛起之路
创始人
2024-05-31 04:15:54
0次
Hive框架
数据仓库
概念
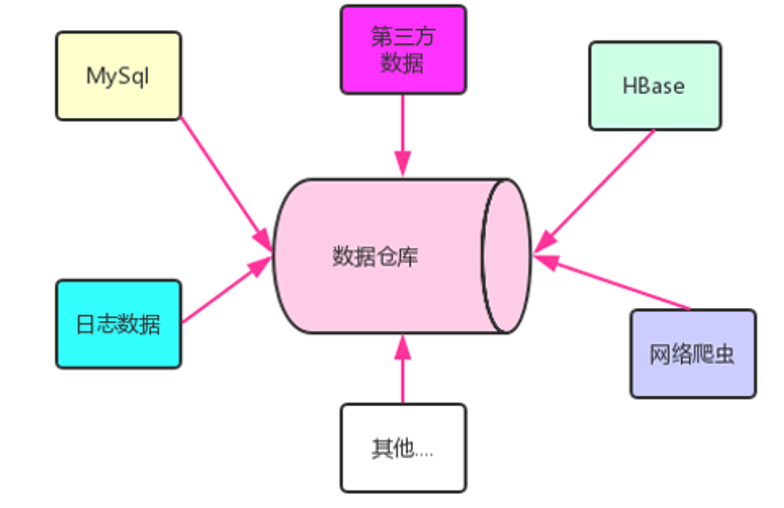
1、数据仓库是企业发展到一定阶段产生的企业第一个阶段:增加用户数,业务量、维持企业则正常运转---》业务数据库(MySQL,Oracle,PSQL...)是为了 让企业活下来,必须要存在。雪中送碳企业第二个阶段:企业面临任务增长瓶颈问题,基于历史数据挖掘出有价值的数据,为企业的决策者提供科学决策支持。----》数据仓库,是为了让企业活的更好,理论可有可无。锦上添花2、数据仓库是来存数据的,存储的数据用户进一步分析的,进一步挖掘的。
3、数据仓库中的来源数据可以多种数据源,只要有利于分析,可以不择手段
4、数据仓库的数据经过分析,最终的输出用于企业的数据分析、数据挖掘、数据报表等方向。
特点
#面向主题性
数仓的数据在分析时,并不是泛泛而去胡乱分析,而是必须先确定好主题,也就是分析时所占的角度(用户主题,销售主题、地域主题、线路主题,征信主题、赔付主题)
#集成性
数仓的数据往往来自多种数据源,需要将多个数据源的数据进行整合,整合时会面临格式不一致,口径不统一问题,则需要对数据进行处理,这个过程也被称为ETL。
#稳定性
数仓中的数据一般有一个数据采集周期(天,周,月),在下一个采集周期到来之前,数仓中的数据是不变的。
#时变性
数仓中的数据在下一个采集周期到来时,需要对数仓的数据进行更新。数仓数据的采集方式是:T+1
数据库和数据仓库的区别

1、数据库面向业务,面向客户,就是OLTP(On-Line Transaction Processing联机事务处理过程)
2、数据仓库面向分析,面向内部开发人员,就是OLAP(Online Analytical Processing 联机分析处理)
数据仓库的分层
-
介绍
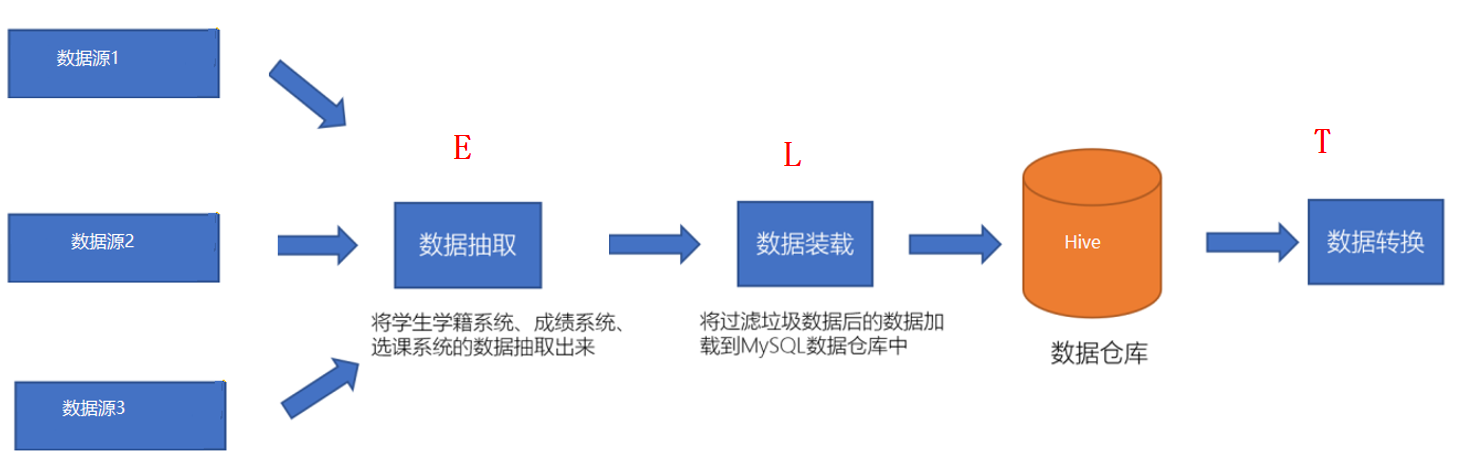
1、数仓的分层是数仓的数据从进来到出去整个数据流向在不同阶段的称呼。 2、每一家公司在数仓分层是不一样的,也没有统一的标准,分层只要适合自己就好 3、分层的好处是在不同的阶段做不同的事情,可以进行明确的阶段分工,提供数据的复用性 4、一般在业界有一个通用的分层标准:ODS层:存放采集后原始结构化数据DW层: 存放对ODS层处理后的数据DWD层:数据拉链表DWB层:降维DWS层:初级聚合APP层:一般存放用于第三方应用的数据


ETL操作
- ETL

- ELT
Hive框架-基础
概述
1、Hive是一个数仓管理工具
2、Hive可以替换掉MapReduce对数仓的数据进行分析
3、Hive有两个功能: 第一个是将数仓的结构化数据映射成一张张的表,第二个是提供类SQL语句对表数据进行分析
4、Hive提供的SQL称为HQL,和普通的SQL的功能类似,但是本质完全不同,底层默认就是MapReduce,但是底层也可以改成其他的计算引擎(Tez,Spark)
5、Hive的表数据是存储在HDFS上
6、Hive本身不存任何数据,Hive只是一个工具#了解:1)Hive是美国的FaceBook公司研发,Presto也是FaceBook研发

架构
-
引入
1、Hive将HDFS上的结构化数据文件映射成一张张的表,哪个文件对应哪张表,每张表的表结构信息这些数据被称为元数据MetaData,都需要保存起来,而Hive本身是不存任何数据的,这些数据在本课程中都由第三方数据库MySQL存储。 2、MetaData元数据由Hive的元数据管理器MateStore服务来负责,负责元数据的读取和写入到MySQL2、HiveSQL底层是MapReduce,而MapReduce的运行必须由Yarn提供资源调度3、结论:如果你要运行Hive,则必须先启动Hadoop

- 结构图

#HiveSQL的执行过程
(0) HiveSQL被提交给客户端
(1) 解释器将HiveSQL语句转换为抽象语法树(AST)
(2) 编译器将抽象语法树编译为逻辑执行计划
(3) 优化器对逻辑执行计划进行优化
(4) 执行器将逻辑计划切成对应引擎的可执行物理计划
(5) 优化器对物理执行计划进行优化
(6) 物理执行计划交给执行引擎执行

Hive的安装
#--------------------Hive安装配置----------------------
# 上传压缩包到/export/software目录里,并解压安装包
cd /export/software/
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /export/server
cd /export/server
mv apache-hive-3.1.2-bin hive-3.1.2#解决hadoop、hive之间guava版本差异
cd /export/server/hive-3.1.2
rm -rf lib/guava-19.0.jar
cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/#添加mysql jdbc驱动到hive安装包lib/文件下
cd /export/server/hive-3.1.2/libmysql-connector-java-5.1.47-bin.jar#修改hive环境变量文件 添加Hadoop_HOME
cd /export/server/hive-3.1.2/conf/
mv hive-env.sh.template hive-env.shvim hive-env.shHADOOP_HOME=/export/server/hadoop-3.3.0
export HIVE_CONF_DIR=/export/server/hive-3.1.2/conf
export HIVE_AUX_JARS_PATH=/export/server/hive-3.1.2/lib
export HADOOP_HEAPSIZE=4096#在/export/server/hive-3.1.2/conf目录下新增hive-site.xml 配置mysql等相关信息
vim hive-site.xmljavax.jdo.option.ConnectionURL jdbc:mysql://node3:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8 javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver javax.jdo.option.ConnectionUserName root javax.jdo.option.ConnectionPassword 123456 hive.server2.thrift.bind.host node3 hive.metastore.uris thrift://node3:9083 hive.metastore.event.db.notification.api.auth false hive.metastore.schema.verification false Hive的交互方式
-
方式1
#在命令行输入hive命令 hiveshow databases; -
方式2
#不进入hive,执行HiveSQL(HQL)命令 hive -e "show databases;"#不进入hive,执行HiveSQL(HQL)脚本 !!!!!! 生产环境 hive -f /root/test/demo.sql -
方式3
#使用Hive第二代客户端来访问 [root@node3 ~]# beeline Beeline version 2.1.0 by Apache Hive beeline> !connect jdbc:hive2://node3:10000 Connecting to jdbc:hive2://node3:10000 Enter username for jdbc:hive2://node3:10000: root Enter password for jdbc:hive2://node3:10000:123456- Hive一键启动脚本
这里,我们写一个expect脚本,可以一键启动beenline,并登录到hive。expect是建立在tcl基础上的一个自动化交
互套件, 在一些需要交互输入指令的场景下, 可通过脚本设置自动进行交互通信。
1、安装expect
yum -y install expect2、 创建脚本
cd /export/server/hive-3.1.2/bin vim beenline.exp#!/bin/expect spawn beeline set timeout 5 expect "beeline>" send "!connect jdbc:hive2://node3:10000\r" expect "Enter username for jdbc:hive2://node3:10000:" send "root\r" expect "Enter password for jdbc:hive2://node3:10000:" send "123456\r" interact3、修改脚本权限
chmod 777 beenline.exp4、启动脚本
expect beenline.exp5、退出beeline
0: jdbc:hive2://node3:10000> !quit6、创建shell脚本
vim /export/server/hive-3.1.2/bin/beeline2 #!/bin/bash expect /export/server/hive-3.1.2/bin/beeline.expchmod 777 /export/server/hive-3.1.2/bin/beeline27、最终调用
beeline2 -
方式4
使用DataGrip连接Hive
Hive的数据库和表操作
操作数据库

-- 1、当你创建一个数据库,则hive自动会在/user/hive/warehouse目录创建一个数据库目录
create database if not exists myhive;
show databases ;-- 2、手动指定数据库映射的文件夹
create database if not exists myhive2 location '/myhive2';
show databases ;-- 3、查看数据库的元数据信息
desc database myhive;-- 4、删除数据库
-- 4.1 可以删除空数据库
drop database myhive2;-- 4.2 如果要删除的数据库里边有表,则必须加 cascade关键字
use myhive;
create table A(id int);
drop database myhive cascade ;
操作表-基本操作
介绍
1、Hive创建表的操作就是指定:表名、表的列名、表的列类型
2、Hive创建表内部的结构和传统的数据库的SQL除了语法相似,内部原理完全不同
3、Hive表文件字段之间默认的分隔符是'\001'
Hive的表数据类型
整形: int
浮点型: float / double / decimal(10,2)
字符串: string
日期类型:年月日:date时分秒:time年月日-时分秒:date_time注意:如果是日期或者时间,则使用字符串可以避免一些不必要的兼容问题
复杂类型:array:数组,集合map :键值对集合struct: 类
表分类
1、Hive表分为两类,一个是内部表,一个是外部表
-
内部表(管理表)
-
语法
create table 表名(字段信息); -
特点
1、内部表认为该表独占表数据文件,该文件不能共享 2、内部表对表文件有绝对的控制权 3、当删除内部表时,表文件会跟着一起删除(同时删除元数据和表数据) 4、所有的非共享表都可以设置为内部表
-
-
外部表
-
语法
create external table 表名(字段信息); -
特点
1、外部表认为该表不能独占表数据文件,文件可以共享 2、外部表对表文件没有绝对的控制权 3、当删除外部表时,表文件不会跟着一起删除(只会删除元数据(映射信息),不会表数据) 4、所有的非共享表都可以设置为内部表 5、如果表数据需要被共享,则可以设置为外部表
-
内部表操作
#1、创建内部表
create table t_covid(dt string comment '日期' ,country string comment '县',state string comment '州',country_code string comment '县编码',cases int comment '确诊人数',deaths int comment '死亡任务'
)comment '美国新冠数据'
row format delimited fields terminated by ','; -- 自定字段之间的分隔符#2、给内部表加载数据-从Linux本地-复制
#将本地的文件复制到表目录:/user/hive/warehouse/myhive.db/t_covid
load data local inpath '/root/test/covid19.dat' into table t_covid;#2、给内部表加载数据-从HDFS加载-剪切
#将HDFS文件剪切到表目录:/user/hive/warehouse/myhive.db/t_covid
load data inpath '/input/covid19.dat' into table t_covid;#3、查看数据
select * from t_covid;
外部表操作
-- 1、创建外部表
drop table if exists t_covid;
create external table t_covid(dt string comment '日期' ,country string comment '县',state string comment '州',country_code string comment '县编码',cases int comment '确诊人数',deaths int comment '死亡任务'
)comment '美国新冠数据'
row format delimited fields terminated by ','; -- 自定字段之间的分隔符-- 2、给内部表加载数据-从Linux本地-复制
#将本地的文件复制到表目录:/user/hive/warehouse/myhive.db/t_covid
load data local inpath '/root/test/covid19.dat' into table t_covid;-- 2、给内部表加载数据-从HDFS加载-剪切
#将HDFS文件剪切到表目录:/user/hive/warehouse/myhive.db/t_covid
load data inpath '/input/covid19.dat' into table t_covid;-- 3、查看数据
select * from t_covid;-- ------演示-让多张表共享同一份数据文件-------
-- 1、创建外部表1映射到文件covid19.dat
drop table if exists t_covid1;
create external table t_covid1(dt string comment '日期' ,country string comment '县',state string comment '州',country_code string comment '县编码',cases int comment '确诊人数',deaths int comment '死亡任务'
)comment '美国新冠数据'
row format delimited fields terminated by ',' -- 自定字段之间的分隔符
location '/input/data';select * from t_covid1;-- 2、创建外部表2映射到文件covid19.dat
drop table if exists t_covid2;
create external table t_covid2(dt string comment '日期' ,country string comment '县',state string comment '州',country_code string comment '县编码',cases int comment '确诊人数',deaths int comment '死亡任务'
)comment '美国新冠数据'
row format delimited fields terminated by ',' -- 自定字段之间的分隔符
location '/input/data';select * from t_covid2;-- 3、创建外部表3映射到文件covid19.dat
drop table if exists t_covid3;
create external table t_covid3(dt string comment '日期' ,country string comment '县',state string comment '州',country_code string comment '县编码',cases int comment '确诊人数',deaths int comment '死亡任务'
)comment '美国新冠数据'
row format delimited fields terminated by ',' -- 自定字段之间的分隔符
location '/input/data';select * from t_covid3;-- 4、删除测试drop table t_covid1;
select * from t_covid1;
select * from t_covid2;drop table t_covid3;
select * from t_covid3;
其他操作
#如何判断一张表是内部表还是外部表,通过元数据查看
desc formatted t_covid;#查看以下信息
Table Type: ,EXTERNAL_TABLE #外部表
Table Type: ,MANAGED_TABLE #内部表
复杂类型操作
-- -----------Hive的复杂类型-Array类型------------
-- 1、数据样例
/*zhangsan beijing,shanghai,tianjin,hangzhouwangwu changchun,chengdu,wuhan,beijing*/
-- 2、建表
use myhive;
create external table hive_array(name string,work_locations array
)
row format delimited fields terminated by '\t' -- 字段之间的分隔符
collection items terminated by ','; -- 数组元素之间的分割符-- 3、加载数据
load data local inpath '/root/hive_data/array.txt' overwrite into table hive_array;-- 4、查询数据
-- 查询所有数据
select * from hive_array;-- 查询work_locations数组中第一个元素
select name, work_locations[0] location from hive_array;-- 查询location数组中元素的个数
select name, size(work_locations) location_size from hive_array;-- 查询location数组中包含tianjin的信息
select * from hive_array where array_contains(work_locations,'tianjin');-- -----------Hive的复杂类型-Map类型------------
-- 1、数据样例
/*
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
2,lisi,father:mayun#mother:huangyi#brother:guanyu,22
3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29
4,mayun,father:mayongzhen# mother:angelababy,26*/
-- 2、建表
create table hive_map(id int,name string,members map,age int
)
row format delimited fields terminated by ','
collection items terminated by '#'
map keys terminated by ':';-- 3、加载数据
load data local inpath '/root/hive_data/map.txt' overwrite into table hive_map;-- 4、查询数据
-- 查询全部数据
select * from hive_map;
-- 根据键找对应的值
select id, name, members['father'] father, members['mother'] mother, age from hive_map;-- 获取所有的键
select id, name, map_keys(members) as relation from hive_map;-- 获取所有的值
select id, name, map_values(members) as relation from hive_map;
-- 获取键值对个数
select id,name,size(members) num from hive_map;-- 获取有指定key的数据
select * from hive_map where array_contains(map_keys(members), 'brother');-- 查找包含brother这个键的数据,并获取brother键对应的值
select id,name, members['brother'] brother from hive_mapwhere array_contains(map_keys(members), 'brother');-- -----------Hive的复杂类型-Struct类型------------
-- 1、数据样例
/*
192.168.1.1#zhangsan:40:男
192.168.1.2#lisi:50:女
192.168.1.3#wangwu:60:女
192.168.1.4#zhaoliu:70:男*/
-- 2、建表
create table hive_struct(ip string,info struct
)
row format delimited fields terminated by '#'
collection items terminated by ':';-- 3、加载数据
load data local inpath '/root/hive_data/struct.txt' overwrite into table hive_struct;-- 4、查询数据
-- 查询全部数据
select * from hive_struct;-- 根据字段查询
select ip,info.name,info.gender from hive_struct; 操作表-分区表和分桶表
介绍
#表的分类:
内部表:内部常规表内部分区表内部分桶表
外部表:外部常规表外部分区表外部分桶表
分区表
-
介绍
#分区就是分文件夹 1、分区表实际是就是对要进行分析的文件进行分类管理 2、本质是将相同特征的文件存放在同一个文件夹下,通过文件夹对数据进行分类 3、分区之后在查询时,可以通过添加条件,避免进行全表扫描,提高查询效率 4、分区表又分为静态分区和动态分区 5、分区表是一种优化手段,是锦上添花的东西,一张表可以没有分区,但是查询效率可能会比较低

-
静态分区
#静态分区就是手动来操作分区的文件夹#----------------------单级分区-一级文件夹-------------------------------- 1、数据样例 /* 2021-01-28,Autauga,Alabama,01001,5554,69 2021-01-28,Baldwin,Alabama,01003,17779,225 2021-01-28,Barbour,Alabama,01005,1920,40 2021-01-28,Bibb,Alabama,01007,2271,51 2021-01-28,Blount,Alabama,01009,5612,98 2021-01-29,Bullock,Alabama,01011,1079,29 2021-01-29,Butler,Alabama,01013,1788,60 2021-01-29,Calhoun,Alabama,01015,11833,231 2021-01-29,Chambers,Alabama,01017,3159,76 2021-01-29,Cherokee,Alabama,01019,1682,35 2021-01-30,Chilton,Alabama,01021,3523,79 2021-01-30,Choctaw,Alabama,01023,525,24 2021-01-30,Clarke,Alabama,01025,3150,38 2021-01-30,Clay,Alabama,01027,1319,50*/-- 2、创建分区表 drop table t_covid; create external table t_covid(dt_value string ,country string ,state string ,country_code string ,cases int ,deaths int ) partitioned by (dt string) -- 这里用来指定分区的字段,字段名字可以随便写 row format delimited fields terminated by ',' -- 自定字段之间的分隔符 ;-- 3、给分区表加载数据 load data local inpath '/root/hive_data/covid-28.dat' into table t_covid partition (dt='2021-01-28'); load data local inpath '/root/hive_data/covid-29.dat' into table t_covid partition (dt='2021-01-29'); load data local inpath '/root/hive_data/covid-30.dat' into table t_covid partition (dt='2021-01-30');-- 4、查看分区表数据 select * from t_covid; --查看所有分区数据select * from t_covid where dt='2021-01-28'; -- 查询指定单个分区的数据 select * from t_covid where dt='2021-01-28' or dt='2021-01-29' ; -- 查询指定多个分区的数据#----------------------单级分区-多级文件夹------------------------------ -- 1、数据样例 /* 2021-02-28,Cleburne,Alabama,01029,1258,28 2021-02-28,Coffee,Alabama,01031,4795,72 2021-02-28,Colbert,Alabama,01033,5686,104 2021-02-28,Conecuh,Alabama,01035,999,23 2021-02-28,Coosa,Alabama,01037,670,19 2021-02-28,Covington,Alabama,01039,3504,87 2021-02-28,Crenshaw,Alabama,01041,1279,47 2021-02-28,Cullman,Alabama,01043,8466,145、 2021-02-29,Dale,Alabama,01045,4235,92 2021-02-29,Dallas,Alabama,01047,3181,108 2021-02-29,DeKalb,Alabama,01049,8052,130 2021-02-29,Elmore,Alabama,01051,8449,131 2021-02-30,Escambia,Alabama,01053,3478,47 2021-02-30,Etowah,Alabama,01055,12359,228 2021-02-30,Fayette,Alabama,01057,1841,37 2021-02-30,Franklin,Alabama,01059,3829,55 2021-02-30,Geneva,Alabama,01061,2205,51 */-- 2、创建分区表 drop table t_covid2; create table t_covid2(dt_value string ,country string ,state string ,country_code string ,cases int ,deaths int ) partitioned by (month string,dt string) -- 这里用来指定分区的字段,字段名字可以随便写 row format delimited fields terminated by ',' -- 自定字段之间的分隔符 ;-- 3、给分区表加载数据 -- 1月份数据load data local inpath '/root/hive_data/covid-28.dat' into table t_covid2partition (month='2021-01',dt='2021-01-28');load data local inpath '/root/hive_data/covid-29.dat' into table t_covid2partition (month='2021-01',dt='2021-01-29');load data local inpath '/root/hive_data/covid-30.dat' into table t_covid2partition (month='2021-01',dt='2021-01-30');-- 2月份数据 load data local inpath '/root/hive_data/2_month/covid-28.dat' into table t_covid2partition (month='2021-02', dt='2021-02-28');load data local inpath '/root/hive_data/2_month/covid-29.dat' into table t_covid2partition (month='2021-02', dt='2021-02-29');load data local inpath '/root/hive_data/2_month/covid-30.dat' into table t_covid2partition (month='2021-02', dt='2021-02-30');-- 4、查询数据 select * from t_covid2; -- 查询所有分区select * from t_covid2 where month = '2021-02'; -- 查询2月份数据select * from t_covid2 where month = '2021-02' and dt = '2021-02-28'; -- 查询2月28号份数据-- 手动添加分区 alter table t_covid2 add partition(month='2021-03',dt='2021-03-28');-- 查看分区文件夹信息 show partitions t_covid2; -
动态分区
#动态分区就是Hive可以根据数据本身的特点来自动创建分区文件夹-
实例1-单级分区
-- 0、样例数据 /* 1 2022-01-01 zhangsan 80 2 2022-01-01 lisi 70 3 2022-01-01 wangwu 90 1 2022-01-02 zhangsan 90 2 2022-01-02 lisi 65 3 2022-01-02 wangwu 96 1 2022-01-03 zhangsan 91 2 2022-01-03 lisi 66 3 2022-01-03 wangwu 96*/ -- 1、设置参数 set hive.exec.dynamic.partition=true; -- 开启动态分区的功能 set hive.exec.dynamic.partition.mode=nonstrict; -- 设置非严格模式-- 2、创建普通非分区表 use myhive; create table myhive.test1 (id int,date_val string,name string,score int ) row format delimited fields terminated by '\t'; ;-- 3、给普通非分区表加载数据 load data local inpath '/root/hive_data/dynamic_partition/a.txt' into table test1; select * from test1;-- 4、创建最终的分区表 drop table test2; create table myhive.test2 (id int,name string,score int ) partitioned by (dt string) row format delimited fields terminated by '\t'; ;-- 5、将普通表的数据查询插入到最终分区表 insert overwrite table test2 select id,name,score,date_val from test1; -- 分区字段一定要放在select的最后-- 6、数据查询 select * from test2; select * from test2 where dt='2022-01-01'; select * from test2 where dt='2022-01-02'; select * from test2 where dt='2022-01-03'; -
实例2-多级分区
-- 0、样例数据 /* 1 2022-01-01 zhangsan m 80 2 2022-01-01 lisi m 70 3 2022-01-01 wangwu f 90 1 2022-01-02 zhangsan f 90 2 2022-01-02 lisi f 65 3 2022-01-02 wangwu m 96 1 2022-01-03 zhangsan f 91 2 2022-01-03 lisi m 66 3 2022-01-03 wangwu m 96 */-- 1、创建普通表 drop table if exists test3; create table test3 (id int,date_val string,name string,sex string,score int )row format delimited fields terminated by '\t'; ; -- 2、给普通表加载数据 load data local inpath '/root/hive_data/dynamic_partition/b.txt' overwrite into table test3; select * from test3;-- 3、创建最终的分区表 drop table test4; create table test4 (id int,name string,score int )partitioned by (dt string,gender string)row format delimited fields terminated by '\t'; ; -- 5、将普通表的数据查询插入到最终分区表 insert overwrite table test4 select id,name,score,date_val,sex from test3; -- 分区的两个字段一定要放在最后-- 6、查询 select * from test4; select * from test4 where dt='2022-01-01' and gender='f'; select * from test4 where gender='f'; -
实例3-自定义分区
-- 0、样例数据 /* 2021-01-28,Autauga,Alabama,01001,5554,69 2021-01-28,Baldwin,Alabama,01003,17779,225 2021-01-28,Barbour,Alabama,01005,1920,40 2021-01-28,Bibb,Alabama,01007,2271,51 2021-01-28,Blount,Alabama,01009,5612,98 2021-01-29,Bullock,Alabama,01011,1079,29 2021-01-29,Butler,Alabama,01013,1788,60 2021-01-29,Calhoun,Alabama,01015,11833,231 2021-01-29,Chambers,Alabama,01017,3159,76 2021-01-29,Cherokee,Alabama,01019,1682,35 2021-01-30,Chilton,Alabama,01021,3523,79 2021-01-30,Choctaw,Alabama,01023,525,24 2021-01-30,Clarke,Alabama,01025,3150,38 2021-01-30,Clay,Alabama,01027,1319,50 2021-02-28,Cleburne,Alabama,01029,1258,28 2021-02-28,Coffee,Alabama,01031,4795,72 2021-02-28,Colbert,Alabama,01033,5686,104 2021-02-28,Conecuh,Alabama,01035,999,23 2021-02-28,Coosa,Alabama,01037,670,19 2021-02-28,Covington,Alabama,01039,3504,87 2021-02-28,Crenshaw,Alabama,01041,1279,47 2021-02-28,Cullman,Alabama,01043,8466,145、 2021-02-29,Dale,Alabama,01045,4235,92 2021-02-29,Dallas,Alabama,01047,3181,108 2021-02-29,DeKalb,Alabama,01049,8052,130 2021-02-29,Elmore,Alabama,01051,8449,131 2021-02-30,Escambia,Alabama,01053,3478,47 2021-02-30,Etowah,Alabama,01055,12359,228 2021-02-30,Fayette,Alabama,01057,1841,37 2021-02-30,Franklin,Alabama,01059,3829,55 2021-02-30,Geneva,Alabama,01061,2205,51 2022-02-28,Geneva,Alabama,01061,2205,51 2022-02-29,Geneva,Alabama,01061,2205,51 2022-02-30,Geneva,Alabama,01061,2205,51 */ -- 1、创建普通表 drop table if exists test5; create table test5 (dt_value string ,country string ,state string ,country_code string ,cases int ,deaths int )row format delimited fields terminated by ','; ; -- 2、给普通表加载数据 load data local inpath '/root/hive_data/dynamic_partition/c.txt' overwrite into table test5; select * from test5;-- 3、创建最终的分区表 drop table test6; create table test6 (country string ,state string ,country_code string ,cases int ,deaths int )partitioned by (year string,month string, dt string)row format delimited fields terminated by ','; ; -- 5、将普通表的数据查询插入到最终分区表 /*year=2022month=01dt=28*/ insert overwrite table test6 select country,state,country_code,cases,deaths,substring(dt_value,1,4), -- 2022substring(dt_value,6,2), -- 0substring(dt_value,-2,2) from test5; -- 分区的两个字段一定要放在最后-- 6、查询 select * from test6; select * from test6 where year='2021' and month ='01';
-
分桶表
-
介绍
1、分桶表和分区表没什么关系 2、分桶表是将表数据分到多个文件,分区表是将数据分到多个文件夹 3、分桶表底层就是MapReduce中分区 4、分桶和分区的区别1)MapReduce的分区就是Hive的分桶2)Hive的分桶就是MapReduce的分区3)Hive的分区和MapReduce分区没什么关系 5、结论:分桶就是分文件 6、分桶的本质就是将大表进行拆分编程小表,小表好join 7、一张表既可以是分区表也可以是分桶表 -
作用
1、提高Join的效率 2、用于数据的抽样(了解)


-
操作
-- 0、样例数据新冠数据:covid19.dat -- 1、开启分桶功能 set hive.enforce.bucketing=true;-- 2、创建普通表 drop table t_covid_common; create table t_covid_common (dt_value string ,country string ,state string ,country_code string ,cases int ,deaths int ) row format delimited fields terminated by ',';-- 3、给普通表加载数据 load data local inpath '/root/hive_data/covid19.dat' overwrite into table t_covid_common; select * from t_covid_common;-- 4、创建分桶表 drop table t_covid_bucket; create table t_covid_bucket (dt_value string ,country string ,state string ,country_code string ,cases int ,deaths int ) clustered by(country_code) into 5 buckets -- country_code就是MapReduce分区中K2 row format delimited fields terminated by ',';-- 5、查询普通表给分桶表加载数据insert overwrite table t_covid_bucket select * from t_covid_common cluster by(country_code); -- 可以在SQL的前边加上explain,查看SQL的执行计划
分区+分桶
-- 内部表
create table A(dt_value string ,country string ,state string ,country_code string ,cases int ,deaths int
)partitioned by (dt string) -- 分文件夹clustered by (country_code) into 3 buckets ; -- 文件夹内部再分文件-- 外部表create external table A(dt_value string ,country string ,state string ,country_code string ,cases int ,deaths int)partitioned by (dt string) -- 分文件夹clustered by (country_code) into 3 buckets ; -- 文件夹内部再分文件
操作表-修改表结构
#这一部分内容和MySQL几乎一样-- 1、创建表:
drop table if exists myhive.score;
create table myhive.score
(sid string,cid string,sscore int
)
row format delimited fields terminated by '\t';-- 2、加载数据
load data local inpath '/root/hive_data/test/score.txt' overwrite into table myhive.score;select * from myhive.score;-- 3、修改表结构
alter table score change column sscore score int;select * from myhive.score;-- 4、清空表数据(只能清空内部表)
truncate table score;
Hive表数据加载的方式
-- 如何给一张表加载数据
-- 1、创建表
drop table if exists myhive.score2;
create table if not exists myhive.score2
(sid string,cid string,sscore int
)
row format delimited fields terminated by '\t';-- 2、表加载数据
-- 方式1-insert into命令 #0颗星
insert into score2 values ('08','02',80),('09','02',80),('10','02',80);-- 方式2-直接通过put命令将文件上传到表目录 #1颗星,测试用
hadoop fs -put score.txt /user/hive/warehouse/myhive.db/score
select * from score2;-- 方式3-使用load命令加载数据 #4颗星,测试和生成都可以用
load data local inpath '/root/hive_data/test/score.txt' overwrite into table myhive.score2;-- 方式4-使用insert into select .... #5颗星、保存结果
insert into score2
select * from score where sscore > 80;-- 方式5-使用create table score5 as select * from score; #1颗星 测试用
-- 先创建表,表的字段和score字段相同,同时score表的数据插入到score3表
create table score3 as select * from score;-- 方式6-使用第三方框架 #5颗星,生产环境
sqoop框架: MySQL/Oracle ===========> Hive表
Kettle框架: MySQL/Oracle ===========> Hive表-- 方式7-HDFS先有数据,后有表 ,建表时使用location关键字
create external table t_covid2(dt string comment '日期' ,country string comment '县',state string comment '州',country_code string comment '县编码',cases int comment '确诊人数',deaths int comment '死亡任务'
)comment '美国新冠数据'
row format delimited fields terminated by ',' -- 自定字段之间的分隔符
location '/input/data';
Hive查询的数据如何导出
-- 方式1-使用命令导出到Linux本地目录中
-- 使用默认分隔符 '\001'
insert overwrite local directory '/root/hive_data/export_hive' select * from score where sscore > 85;-- 手动指定分隔符 ','
insert overwrite local directory '/root/hive_data/export_hive'
row format delimited fields terminated by ','
select * from score where sscore > 85;-- 方式2-使用命令导出到HDFS目录中(去掉local)
insert overwrite directory '/output/hive_data'
row format delimited fields terminated by ','
select * from score where sscore > 85;-- 方式3-使用SQL导出到其他表 !!!!!!!!!!!!!!!!!!
insert overwrite into table 目标表
select 字段 from 原表 where 条件;-- 方式4-使用第三方框架导出其他的存储平台(HBase、Spark、MySQL) !!!!!!!!!!!!
sqoop
Kettle
Datax
Presto
Hive的查询操作
SQL的书写顺序

#HiveSQL、PrestoSQL、SparkSQL、FlinkSQL、DorisSQL、HBaseSQL
SQL的执行顺序

Hive的基本查询
-- 1、全表查询
select *
from t_covid;-- 2、指定列查询
select state, cases
from t_covid; -- 默认列名select state, cases + 10 as new_cases
from t_covid; -- 指定列别名
select state, cases + 10 new_cases
from t_covid; -- 指定列别名drop table t_covid;
create table t_covidx
(dt_value string,country string,state string,country_code string,cases int,deaths int
)row format delimited fields terminated by ',' -- 自定字段之间的分隔符
;
select *
from t_covid;/*1、在Hive的一些版本中,当使用聚合函数来统计时,发现SQL语句没有返回返回任何结果2、因为Hive默认是去MySQL的元数据中获取文件的行数、但是元数据中默认行数都是03、我们需要设置一个参数,不让SQL去元数据中获取行数,而是执行这条SQL对文件进行出来,自己来统计行数*/
set hive.compute.query.using.stats=false;-- 开启Hive的本地模式,加快查询速度
set hive.stats.column.autogather=false;
set hive.exec.mode.local.auto=true;
--开启本地mr-- 3、聚合函数
-- 1)求总行数(count)
select count(*)
from t_covid; -- 求表的总行数,只要有一列不为NULL,则统计
select count(1)
from t_covid; -- 求表的总行数,只要有一列不为NULL,则统计
select count(state)
from t_covid;
-- 求state列有多少行,不会统计NULL值--2)求分数的最大值(max)
select max(cases) max_cases
from t_covid;-- 3)求分数的最小值(min)
select min(cases) min_cases
from t_covid;-- 4)求分数的总和(sum)
select sum(cases) total_cases
from t_covid;-- 5)求分数的平均值(avg)
select round(avg(cases), 2)
from t_covid;-- 4、Limit 分区查询
select *
from t_covid;
select *
from t_covid
limit 3; -- 查询前3条select *
from t_covid
limit 3,2; -- 从索引3开始先显示,显示2条 ,索引从0开始
Hive的条件查询
select *
from t_covid
where state = 'Alaska';select *
from t_covid
where deaths between 1000 and 2000; -- [1000,2000] 包含左边和右边select *
from t_covid
where deaths between 1000 and 2000; -- [1000,2000] 包含左边和右边select *
from t_covid
where state = 'Alaska'or state = 'New Mexico';
select *
from t_covid
where state in ('Alaska', 'New Mexico');
-- 和上边等价-- 查询州名以S开头的疫情数据
select *
from t_covid
where state like 'S%';
-- 查询州名包含s的疫情数据
select *
from t_covid
where state like '%s%';select *
from t_covid
where state rlike '[s]';
-- 做用同上-- 查询确诊病例数大于50000,同时死亡病例数大于1000的信息
select *
from t_covid
where cases >= 50000and deaths >= 1000;
-- 查询阿拉斯加州和新墨西哥州的疫情数据
select *
from t_covid
where state = 'Alaska'or state = 'New Mexico';-- 查询除了阿拉斯加州和新墨西哥州以外的疫情数据
select *
from t_covid
where state not in ('Alaska', 'New Mexico');select *
from t_covid
where deaths not between 1000 and 2000;
Hive的分组查询
-- 分组之后,select的后边,只能跟分组字段和聚合函数
-- 每个州的确诊病例总数
select state, sum(cases)
from t_covid
group by state;select state, sum(cases) total_cases
from t_covid
group by state
having total_cases >= 500000;
Hive的join查询
-- 7、Hive的join操作create table teacher (tid string,tname string) row format delimited fields terminated by '\t';
load data local inpath '/root/hive_data/test/teacher.txt' overwrite into table teacher;create table course (cid string,c_name string,tid string) row format delimited fields terminated by '\t';
load data local inpath '/root/hive_data/test/course.txt' overwrite into table course;-- 1) 内连接
-- 求两张表的交集
select * from teacher join course ; -- 笛卡尔集
select * from course;select * from teacher inner join course on teacher.tid = course.tid;
select * from teacher join course on teacher.tid = course.tid;
select * from teacher , course where teacher.tid = course.tid; -- 同上-- 2) 外连接
-- 2.1 左外连接
-- 以左表为主,左表的数据全部输出,右表有对应的数据就输出,没有对应的就输出NULL
insert into teacher values ('04','赵六');
select * from teacher;select * from teacher left join course on teacher.tid = course.tid;-- 2.2 右外连接-- 以右表为主,右表的数据全部输出,左表有对应的数据就输出,没有对应的就输出NULL
insert into course values ('04','地理','05');
select * from course;select * from teacher right join course on teacher.tid = course.tid;-- 2.3 满外连接select * from teacher full join course on teacher.tid = course.tid;select*
from A表 a left join B表 b on a.id = b.idleft join C表 c on b.id = c.idleft join D表 d on c.id = d.id;Hive的排序查询
-- 8、Hive的排序查询
-- 8.1 order By
-- 全局排序,要求只能有一个Reduce
select * from t_covid order by cases desc limit 10;-- distribute by + sort by
-- distribute by 对数据进行分区,sort by对每一个分区的数据进行排序
-- 按照州对数据进行分区,对每一个分区的州数据按照确诊病例进行降序排序
-- state.hash值 % reduce个数
set mapreduce.job.reduces = 55;insert overwrite local directory '/root/hive_data/export_hive'
select * from t_covid distribute by state sort by cases desc;-- cluster by
-- 如果你的distribute by和sort by后边的字段相同时,可以使用 cluster by来简化
-- 只能是升序排序
cluster by 字段 =====> distribute by 字段 + sort by 字段;set mapreduce.job.reduces = 10;
select * from t_covid distribute by state sort by cases desc;
select * from t_covid cluster by state ; -- 不能等价于以上写法
Hive的函数
Hive的内置函数
-
数学函数
-- 四舍五入 select round(3.555);-- 指定位数四舍五入 select round(3.555,2);-- 向下取整 select floor(3.9);-- 向上取整 select ceil(3.1);-- 取随机数 select floor((rand() * 100) + 1); -- 1到100之间的随机数-- 绝对值 select abs(-12);-- 几次方运算 select pow(2,4); -
字符串函数
-- URL路径解析 select parse_url('https://www.baidu.com/info/s?word=bigdata&tn=25017023_2_pg', 'HOST'); -- www.baidu.com select parse_url('https://www.baidu.com/info/s?word=bigdata&tn=25017023_2_pg', 'PATH'); -- /info/s select parse_url('https://www.baidu.com/info/s?word=bigdata&tn=25017023_2_pg', 'QUERY');-- /info/s select parse_url('https://www.baidu.com/info/s?word=bigdata&tn=25017023_2_pg', 'QUERY'); -- word=bigdata&tn=25017023_2_pg select parse_url('https://www.baidu.com/info/s?word=bigdata&tn=25017023_2_pg', 'QUERY','word'); -- bigdata select parse_url('https://www.baidu.com/info/s?word=bigdata&tn=25017023_2_pg', 'QUERY','tn'); -- 25017023_2_pg-- json数据解析 select get_json_object('{"name": "zhangsan","age": 18, "preference": "music"}', '$.name'); select get_json_object('{"name": "zhangsan","age": 18, "preference": "music"}', '$.age'); select get_json_object('{"name": {"aaa":"bbb"}}', '$.name.aaa');-- 字符串拼接 select concat(rand(),'-',sid) as sid, sname from student; select concat(rand(),'-',sid) as sid, sname from student;-- 字符串拼接,带分隔符 select concat_ws('-','2022','10','15'); select log10(100)-- 字符串截取 select substr('2022-12-23 10:13:45',1,4); -- 2022 select substr('2022-12-23 10:13:45',6,6); -- 12-- 字符串替换 select regexp_replace('foobar', 'oo|ar', '');-- 字符串切割 select split('2022-12-23','-'); -
日期函数
select unix_timestamp(); -- 离1970年1月1日秒值,晚了8个小时 select `current_date`(); -- 获取当前的年月日 select `current_timestamp`(); -- 获取当前的年月日,时分秒select from_unixtime(1677584757, 'yyyy-MM-dd HH:mm:ss'); select from_unixtime(unix_timestamp() + 8 * 3600, 'yyyy-MM-dd HH:mm:ss');select unix_timestamp('20111207 13:01:03', 'yyyyMMdd HH:mm:ss');select unix_timestamp('2022年12月23日 11点22分36秒', 'yyyy年MM月dd日 HH点mm分ss秒');select from_unixtime(unix_timestamp('2022年12月23日 11点22分36秒', 'yyyy年MM月dd日 HH点mm分ss秒'),'yyyy-MM-dd HH:mm:ss');select date_format('2022-1-1 3:5:6', 'yyyy-MM-dd HH:mm:ss'); -- 日期格式转换 select to_date('2011-12-08 10:03:01'); -- 获取年月日select year('2011-12-08 10:03:01') + 10; select substring('2011-12-08 10:03:01', 1, 4) + 10; select hour('2011-12-08 10:03:01');select `dayofweek`('2023-02-28') - 1; -- 默认周日是第一天 select weekofyear('2023-02-28'); -- 获取今年的第几周 select quarter('2023-02-28'); -- 获取季度select datediff('2023-02-28', '2008-08-08'); -- 日期的差值 select abs(datediff('2008-08-08', '2023-02-28'));select date_add('2023-02-28', 100); -- 日期向后推移 select date_add('2023-02-28', -100); -- 日期向前推移 select date_sub('2023-02-28', 100); -
条件判断函数
-- ------------------if语句---------------------------- select if(TRUE, 100, 200); select if(FALSE, 100, 200);select *,if(sscore >= 60, '及格', '不及格') as flag from score;-- ------------------case语句---------------------------- /*口径不统一:A表:性别: m fB表:性别:男,女*/ select *,case sexwhen 'm' then '男'when 'f' then '女'end as gender from test3;select *,casewhen sscore >= 90 then '优秀'when sscore >= 80 then '良好'when sscore >= 60 then '及格'when sscore < 60 then '不及格'else '其他' end from score;select *,casewhen salary >= 100000 then '高薪'where salary >= 5000 then '工薪'when sscore < 3000 then '屌丝'else '其他' end from score; -
类型强转函数
-- 类型转换函数 select cast(12.95 as int); select cast('20190607' as int); select cast('2020-12-05' as date); select cast(123 as string);
行转列和列转行函数

行转列
/*
20 SMITH
30 ALLEN
30 WARD
20 JONES
30 MARTIN
30 BLAKE
10 CLARK
20 SCOTT
10 KING
30 TURNER
20 ADAMS
30 JAMES
20 FORD
10 MILLER
*/-- 1、建表
create table emp(
deptno int,
ename string
) row format delimited fields terminated by '\t';-- 2、加载数据
load data local inpath '/root/test/test1.txt' into table emp;-- 3、实现
select * from emp;set hive.stats.column.autogather=false;
set hive.exec.mode.local.auto=true; --开启本地mr-- collect_list可以将每一组的ename存入数组,不去重
select deptno,collect_list(ename) from emp group by deptno;-- collect_list可以将每一组的ename存入数组,去重
select deptno,collect_set(ename) from emp group by deptno;
-- collect_list可以将每一组的ename存入数组,去重,concat_ws将数组中的每一个元素进行拼接
select deptno,concat_ws('|',collect_set(ename)) as enames from emp group by deptno;
列转行
-- 1、建表
create table emp2(deptno int,names array
)
row format delimited fields terminated by '\t'
collection items terminated by '|';-- 2、加载数据
load data local inpath '/root/test/test2.txt' into table emp2;select * from emp2;-- 3、SQL实现
select explode(names) from emp2; -- 此方法行不通-- 将原来的表emp2和炸开之后的表进行内部的关联,判断炸开的每一行都来自哪个数组
select * from emp2 lateral view explode(names) t as name;-- t是explode生成的函数的别名,name是explode列的别名
select deptno, name from emp2 lateral view explode(names) t as name
Hive的窗口函数
-
分组排序函数
/* user1,2018-04-11,5 user2,2018-04-12,5 user2,2018-04-12,5 user1,2018-04-11,5 user2,2018-04-13,6 user2,2018-04-11,3 user2,2018-04-12,5 user1,2018-04-10,1 user2,2018-04-11,3 user1,2018-04-12,7 user2,2018-04-12,5 user1,2018-04-13,3 user2,2018-04-13,6 user1,2018-04-14,2 user1,2018-04-15,4 user1,2018-04-16,4 user2,2018-04-10,2 user2,2018-04-14,3 user1,2018-04-11,5 user2,2018-04-15,9 user2,2018-04-16,7 */ -- 1、建表 CREATE TABLE test_window_func1( userid string, createtime string, --day pv INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';-- 2、加载数据: load data local inpath '/root/test/test3.txt' overwrite into table test_window_func1;select * from test_window_func1;-- 3、需求:按照用户进行分组,并且在每一组内部按照pv进行降序排序 -- row_number,rank,dense_rank /*partition by userid 按照哪个字段分组,等价于group byorder by pv desc 组内按照哪个字段排序*/ select *, row_number() over (partition by userid order by pv desc) as rk_row_number, -- 1 2 3 4 5 rank() over (partition by userid order by pv desc) as rk_rank, -- 1 2 3 3 5 dense_rank() over (partition by userid order by pv desc) as rk_dense_rank -- 1 2 3 3 4 from test_window_func1;-- 如果没有分组partition by 的情况 -- 将整整表看做是一组 select *, dense_rank() over (order by pv desc) as rk_dense_rank from test_window_func1;-- 如果没有分组order by 的情况select *, row_number() over (partition by userid ) as rk_row_number, -- 1 2 3 4 5 rank() over (partition by userid ) as rk_rank, -- 1 1 1 1 1 dense_rank() over (partition by userid ) as rk_dense_rank -- 1 1 1 1 1 from test_window_func1;-- 需求:求每一组的PV最多的前3个:每组的Top3-- 方式1 select * from (select*,dense_rank() over (partition by userid order by pv desc) as rkfrom test_window_func1 ) t where rk <= 3;-- 方式2 with t as (select*,dense_rank() over (partition by userid order by pv desc) as rkfrom test_window_func1 ) select * from t where rk <= 3; -
聚合开窗函数
-- ----------------聚合开窗----------------- 默认是从开头累加到当前行 select userid,createtime,pv, sum(pv) over(partition by userid order by createtime ) as pv1 from test_window_func1;-- 作用同上 select userid,createtime,pv, sum(pv) over(partition by userid order by createtimerows between unbounded preceding and current row ) as pv1 from test_window_func1;-- 指定从上一行加到当前行 select userid,createtime,pv,sum(pv) over(partition by userid order by createtimerows between 1 preceding and current row ) as pv1 from test_window_func1;-- 指定从上一行加到下一行 select userid,createtime,pv,sum(pv) over(partition by userid order by createtimerows between 1 preceding and 1 following ) as pv1 from test_window_func1;-- max select userid,createtime,pv, max(pv) over(partition by userid order by createtime ) as pv1 from test_window_func1; -- min select userid,createtime,pv, min(pv) over(partition by userid order by createtime ) as pv1 from test_window_func1; -
lag和lead函数
-- lag 和lead函数-- 将pv列的上一行数据放在当前行 select *,lag(pv,1,0) over(partition by userid order by createtime) from test_window_func1;-- 将pv列的下一行数据放在当前行 select *,lead(pv,1,0) over(partition by userid order by createtime) from test_window_func1;-- ------------------模拟漏斗模型----------------------------- /* stage1 1000 stage2 800 stage3 50 stage4 2 */ -- 1、创建表 create table demo( stage string, num int) row format delimited fields terminated by '\t' ;-- 2、加载数据 load data local inpath '/root/test/test4.txt' into table demo;select * from demo;-- 3、代码实现 with t as ( select *,lag(num,1,-1) over (order by stage) as pre_num from demo ) select *, concat(floor((num / pre_num)*100),'%') as rate from t where stage > 'stage1';


-
开窗面试题
#需求:有一张表,三个字段:部门号,员工名字,员工的薪资,去除每个部门的最低和最高工资,求每个部门的平均薪资-- 1、建表; drop table demo2; create table demo2( deptno int, ename string, salary int) row format delimited fields terminated by '\t' ; -- 2、加载数据; load data local inpath '/root/test/test5.txt' overwrite into table demo2;select * from demo2;-- 2、过滤每一组的最大值和最小值; with t as ( select*,dense_rank() over (partition by deptno order by salary desc ) as rk1, -dense_rank() over (partition by deptno order by salary asc ) as rk2 from demo2 ) select deptno,`floor`(avg(salary)) from t where rk1 != 1 and rk2 != 1 group by deptno;
Hive的自定义函数
介绍
1、当在进行数据分析时,如果Hive现存的所有函数都无法满足需求,则可以自定义函数
2、自定义函数的分类UDF : 一进一出的函数 substring、floor、reverse !!!!UDTF: 一进多出的函数 explode !!!!UDAF: 多进一出的函数 聚合函数(count、max、min)
UDF函数的定义
-
1、加载pom.xml依赖
org.apache.hive hive-exec 3.1.2 org.apache.hadoop hadoop-common 3.1.4 -
2、自定义类继承UDF类,并重写evaluate方法
import org.apache.hadoop.hive.ql.exec.UDF;/*手机号: 13812345678 ---> 138****5678*/ @SuppressWarnings("all") public class MyUDF extends UDF {public String evaluate(String phoneNum){String str1 = phoneNum.substring(0,3);String str2 = phoneNum.substring(7);return str1 + "****" + str2;}} -
3、将自定义类代码打成jar包,添加造Hive的lib目录,并重命名
mv module_hive-1.0-SNAPSHOT.jar my_udf.jar -
4、在hive的客户端添加我们的jar包
hive> add jar /export/server/hive-3.1.2/lib/my_udf.jar -
5、注册函数
-- 注册临时函数 hive> create temporary function phone_num_enc as 'pack01_udf.MyUDF';-- 注册永久函数 hive> create function phone_num_enc2 as 'pack01_udf.MyUDF'using jar 'hdfs://node1:8020/hive_func/my_udf.jar'; -
6、使用自定义函数
hive> select phone_num_enc('13812345678');hive> select phone_num_enc2('13812345678');
UDTF函数的定义
- 需求1

-
代码实现
package pack02_udtf;import org.apache.hadoop.hive.ql.exec.UDFArgumentException; import org.apache.hadoop.hive.ql.metadata.HiveException; import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory; import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.util.ArrayList; import java.util.List; import java.util.function.ObjDoubleConsumer;public class MyUDTF extends GenericUDTF {private final Object[] forwardList = new Object[1];/*该方法只会执行一次,用于初始化该方法用来定义:UDTF输出结果有几列,每一列的名字和类型*/@Overridepublic StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {//设置UDTF函数输出的每一列的名字ListfieldNames = new ArrayList<>();//设置列名fieldNames.add("column_01");//fieldNames.add("column_02");//fieldNames.add("column_03");//设置UDTF函数输出的每一列的类型List fieldOIs = new ArrayList () ;//检查器列表//第一列:String类型fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);第二列:Int类型//fieldOIs.add(PrimitiveObjectInspectorFactory.javaIntObjectInspector);第三列:Double类型//fieldOIs.add(PrimitiveObjectInspectorFactory.javaDoubleObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);}//每来一行数据,该方法就会调用一次/*select my_udtf(字段,分隔符)select my_udtf(‘zookeeper,hadoop,hdfs,hive,MapReduce’,',')Object[] objects = {‘zookeeper,hadoop,hdfs,hive,MapReduce’,',' }*/@Overridepublic void process(Object[] objects) throws HiveException {//1:获取原始数据String line = objects[0].toString(); //‘zookeeper,hadoop,hdfs,hive,MapReduce’//2:获取数据传入的第二个参数,此处为分隔符String splitKey = objects[1].toString(); // ','//3.将原始数据按照传入的分隔符进行切分String[] wordArray = line.split(splitKey); // String[] wordArray = {'zookeeper','hadoop'..}//4:遍历切分后的结果,并写出for (String word : wordArray) {//将每一个单词添加值对象数组forwardList[0] = word; //zookeeper 第一列 这里只给0索引赋值,则输出的结果只有一列//forwardList[1] = word2; //zookeeper 第二列//将对象数组内容写出,每写一次就会多出一行forward(forwardList);}}@Overridepublic void close() throws HiveException {} } -
测试
UDTF的测试方法和UDF一样 -
需求2

-
代码
package pack02_udtf;import org.apache.hadoop.hive.ql.exec.UDFArgumentException; import org.apache.hadoop.hive.ql.metadata.HiveException; import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory; import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.util.ArrayList; import java.util.List;public class MyUDTF2 extends GenericUDTF {private final Object[] forwardArray = new Object[2];/*该方法只会执行一次,用于初始化该方法用来定义:UDTF输出结果有几列,每一列的名字和类型*/@Overridepublic StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {//设置UDTF函数输出的每一列的名字ListfieldNames = new ArrayList<>();//设置列名fieldNames.add("name");fieldNames.add("age");//设置UDTF函数输出的每一列的类型List fieldOIs = new ArrayList () ;//检查器列表//第一列:String类型fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);第二列:Int类型fieldOIs.add(PrimitiveObjectInspectorFactory.javaIntObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);}//每来一行数据,该方法就会调用一次/*"jack:18,rose:19,jerry:20,tom:28"select my_explode2(字段,分隔符)select my_explode2("jack:18,rose:19,jerry:20,tom:28",',',':')Object[] objects = {'jack:18,rose:19,jerry:20,tom:28',',',':'}*/@Overridepublic void process(Object[] objects) throws HiveException {//1:获取原始数据String line = objects[0].toString(); //'jack:18,rose:19,jerry:20,tom:28'//2:获取输入的第一个分隔符String splitKey1 = objects[1].toString(); // ','//3:获取输入的第二个分隔符String splitKey2 = objects[2].toString(); // ':'//4、先将数据按照第一个分隔符(逗号),切成一个个的减值对String[] keyValueArray = line.split(splitKey1); //{'jack:18','rose:19','jerry:20','tom:28'}//5、遍历数组,按照第一个分隔符(冒号),对每个键值对进行切割,获取键和值for (String keyValue : keyValueArray) {String[] kvArray = keyValue.split(splitKey2); //{'jack',18}//5.1 获取键String key = kvArray[0];//5.2 获取值int value = Integer.parseInt(kvArray[1]);//6、将键存入数组的0索引,作为第一列输出forwardArray[0] = key;//6、将值存入数组的1索引,作为第二列输出forwardArray[1] = value;//7、将数组写出,因为数组中有两个索引有值,所以会输出两列forward(forwardArray);}}@Overridepublic void close() throws HiveException {} }
Hive的压缩和存储
压缩算法
-
分类
#1、Hive的压缩分成两类: Map端压缩 Reduce端压缩#2、Hive的底层就是MapReduce,通过引入压缩可以提高Map端和Reduce端网络传输的效率,同时可以节省磁盘空间的占用 -
常见的压缩算法
Hive几乎可以支持市面上大多数的压缩算法:deflate、gzip、bzip2、lzo、snappy -
如果选择一个好的压缩算法
1、要考虑压缩比: 节省磁盘空间 2、要考虑解压速度: 提高查询速度 -
操作
-- --------------------设置Map端压缩-------------------------- -- 大开关 set hive.exec.compress.intermediate=true; -- 小开关 set mapreduce.map.output.compress=true;-- 设置压缩算法 set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;select state,sum(cases) from t_covid group by state ; -- 无压缩 32s select state,sum(cases) from t_covid group by state ; -- 有压缩 25sexplain select state,sum(cases) from t_covid group by state ; -- 无压缩 32s-- --------------------设置Reduce端压缩---------------------------- 设置Reduce端压缩 -- 1)开启hive最终输出数据压缩功能 set hive.exec.compress.output=true; -- 2)开启mapreduce最终输出数据压缩 set mapreduce.output.fileoutputformat.compress=true; -- 3)设置mapreduce最终数据输出压缩方式 set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec; -- 4)设置mapreduce最终数据输出压缩为块压缩 set mapreduce.output.fileoutputformat.compress.type=BLOCK;-- 5)测试一下输出结果是否是压缩文件insert overwrite local directory '/export/data/compress' select state,sum(cases) from t_covid group by state ;create table t_covidxx as select state,sum(cases) from t_covid group by state ; select * from t_covidxx;
存储格式
-
分类
#行存储:以行为单位存储 1、行存储是Hive默认的存储方式,也是最通用的存储方式 2、行存储格式:TEXTFILE(默认行式存储)、SEQUENCEFILE#列存储:以列为单位存储 1、列存储是Hive最适合的存储方式,也是Hive中用的最多的存储格式 2、列存储格式:ORC、PARQUET。 -
优缺点
#行存储 = 优点 1、使用行查询效率高(select * from t_covid) = 缺点 1、使用列查询效率低(select dt_value,state from t_covid)#列存储 = 优点 1、使用列查询效率高(select dt_value,state from t_covid) = 缺点 1、使用行查询效率低(select * from t_covid)###########结论########### 1、由于在生产环境一般都是列查询,所以一般使用列式存储,查询效率较高 2、本课程所有的Hive存储格式都是用ORC,ORC格式自带ZLIB压缩算法 -
操作
-- ------------------Hive的存储格式------------------- -- TextFilecreate temporary table log_text ( -- 18.13M track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE ;load data local inpath '/export/data/hivedatas/log.data' into table log_text ;select *FROM log_text;-- ORC create table log_orc ( -- 2.78M track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS ORC ;-- ORC格式的表,不能使用load加载,需要使用insert into ... select -- load data local inpath '/export/data/hivedatas/log.data' into table log_orc ; insert into table log_orc select * from log_text;-- ORC格式自带ZLIB压缩算法:18.13M --->2.78 MB select *FROM log_orc;-- PARQUET create table log_parquet ( -- 13.09MB track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS PARQUET ;-- PARQUET格式的表,不能使用load加载,需要使用insert into ... select -- load data local inpath '/export/data/hivedatas/log.data' into table log_orc ; insert into table log_parquet select * from log_text;-- 18.13M --->13.09M select * FROM log_parquet;--- 查看查询速度 select count(*) FROM log_text; -- 25 s 497 ms select count(*) FROM log_orc; -- 75 ms select count(*) FROM log_parquet; -- 87 ms
存储格式 + 压缩算法
-
介绍
1、我们的存储格式如果选定为ORC,则可以搭配其他的压缩算法 2、搭配方式orc + 无压缩算法orc + 自带的压缩算法zliborc + snappy压缩算法

-- 存储格式 + 压缩算法-- orc + 无压缩
drop table log_orc_none;
create table log_orc_none( -- 7.69 MBtrack_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="NONE");insert overwrite table log_orc_none select * from log_text;
select * from log_orc_none;-- orc + zlib
drop table log_orc_none;
create table log_orc_none( -- 7.69 MBtrack_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="ZLIB");insert overwrite table log_orc_none select * from log_text;
select * from log_orc_none;-- orc + snappy
drop table log_orc_snappy;
create table log_orc_snappy( -- 3.75 MBtrack_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");insert overwrite table log_orc_snappy select * from log_text;
select * from log_orc_snappy;Hive的调优
本地模式
-
介绍
1、本地模式是当数据量比较小的情况下,可以在单台机器上完成计算任务,执行时间大大缩短 2、本地模式一般不会走MapReduce 3、本地模式一般用于测试 4、如果开启了本地模式,但是你的数据量超过了设置的阈值,则Hive也不会使用本地模式 -
操作
set hive.stats.column.autogather=false; set hive.exec.mode.local.auto=true; --开启本地mr--设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128Mset hive.exec.mode.local.auto.inputbytes.max=51234560; --设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4 set hive.exec.mode.local.auto.input.files.max=10;
空Key的处理
空Key的过滤
#空key能够过滤的前提是由空Key的数据对分析没有意义,必须过滤掉#不过滤(效率低)
select * from A left join B on A.id = B.id#过滤(效率高)
select * from (select * from A where id is not null) A left join B on A.id = B.id

空Key的转换
- 分析
#有时空key数据不能直接顾虑掉,要保留下来用于后续的分析
select * from A left join B on A.id = B.idselect * from (select if(id is null,floor((rand() * 1000000) + 1,id) id,name) left join Bon A.id = B.id

-
操作
-- 1、A表,有大量的空值 drop table nullidtable; create table nullidtable(id string, time_val bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t'; load data local inpath '/export/data/hivedatas/hive_have_null_id/*' into table nullidtable; select * from nullidtable limit 10;-- 2、B表,没有大量的空值 drop table ori; create table ori(id string, time_val bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t'; load data local inpath '/export/data/hivedatas/hive_big_table/*' into table ori; select * from ori limit 10;-- 3、将A表和B表的join结果存入该表 drop table jointable; create table jointable(id string, time_val bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by '\t';-- 测试一下空值是否被替换为随机数 select concat('r',if(id is null,floor((rand() * 1000000) + 1),id)) id,time_val,uid,keyword, url_rank,click_num,click_url from nullidtable;-- 测试处理空值的join with A as (select concat('r',if(id is null,floor((rand() * 1000000) + 1),id)) id,time_val,uid,keyword, url_rank,click_num,click_url from nullidtable ) select A.*, B.* from nullidtable Aleft join ori B on A.id = B.id;-- 测试如果不处理空值,则会发生数据倾斜,去看8088页面,发现某一个Reduce迟迟不结束 with A as (select * from nullidtable ) select A.*, B.* from nullidtable Aleft join ori B on A.id = B.id;
并行执行
1、当一条SQL中的语句,如果前后没有依赖关系,这些语句可以并行执行select * from A ???union allselect * from B ???
2、开启并行执行:set hive.exec.parallel=true; --打开任务并行执行set hive.exec.parallel.thread.number=16; --同一个sql允许最大并行度,默认为8。
严格模式
- 介绍
1、所谓的严格模式,就是给你写HiveSQL加一个限制,如果你写的SQL效率太低,则直接终止
2、Hive默认是非严格模式,你的SQL想怎么写就怎么写,效率低也无所谓
3、如何设置严格模式:set hive.mapred.mode = strict; --开启严格模式set hive.mapred.mode = nostrict; --开启非严格模式-
操作
#在严格模式下,对于分区表,查询时必须加分区条件 select * from t_covid2 where month='2021-03';#在严格模式下,使用Order By排序时,必须加limit关键字 select * from t_covid2 where month='2023-01' order by cases limit 3;#限制笛卡尔积的查询,join时必须加on条件 select * from A join B on 条件
存储格式和压缩算法
在生产环境中,选择合适的存储格式和压缩方式有利于数据分析ORC存储 + Snappy压缩
Hive的面试题
1、你用的Hive的版本
2、Hive和Hadoop的关系
3、Hive中内部表和外部表的区别
4、Hive中分区表和分桶表的区别
5、Hive表加载数据的方式有哪些?
6、你用过哪些Hive的开窗函数,什么时候需要使用开窗函数?当你想实现分组(group by),聚合(sum)操作,但是还想保留数据的明细,此时要使用开窗函数
7、笔试:写行转列和列转行代码,问你collect_set 和 collect_list
8、Hive自定义UDF的步骤
9、你们项目中Hive数据文件的存储格式和压缩算法是什么
10、你知道有哪些Hive的调优方式
相关内容
热门资讯
工会大会流程及主持词
工会大会流程及主持词 篇一:工会主持词 ……市……委工会成立大会 主 持 词 各位领导,会员...
电影大话西游经典台词
电影大话西游经典台词 如果你看星爷的大话西游觉得好玩有趣充满了幽默感,实话说你并没有看懂过。当你想...
五一晚会主持词
五一晚会主持词(通用10篇) 主持词的写作要突出活动的主旨并贯穿始终。在如今这个时代,我们对主持词...
笑傲江湖周云鹏的脱口秀台词
笑傲江湖周云鹏的脱口秀台词 地球人都是中国有个喜剧之王周星驰,而周云鹏才是脱口秀中的剧场之王!看过...
yy活动主持词
yy活动主持词 女:亲爱的朋友们!大家晚会好!我是今晚的主持人XXX,欢迎您走进“鹊桥会”——丫丫...
升国旗仪式主持词
升国旗仪式主持词(精选12篇) 主持词可以采用和历史文化有关的表述方法去写作以提升活动的文化内涵。...
主持词范文
主持词范文 主持词写作 主持词的写作没有固定格式,它的最大特点就是富有个性。不同内容的活动,不同...
主持人正式节目优秀串词
主持人正式节目优秀串词 第一篇:《6.1主持人正式节目串词》 尊敬的老师们、亲爱的同学们大家好:...
篮球赛闭幕式主持词
篮球赛闭幕式主持词范文3篇 篇一:篮球赛闭幕式主持词尊敬的各位领导、各位来宾,裁判员、教练员、运动...
公司晚会主持稿
公司晚会主持稿【三篇】 在现实社会中,各种主持稿频频出现,主持稿大体上可分为会议主持稿、文艺演出晚...
红歌会主持词
红歌会主持词范文 相信我们身边会有喜欢唱红歌的人,下面小编为大家带来了2篇红歌会主持词范文,欢迎大...
圣诞晚会主持词开场白
圣诞晚会主持词开场白(通用12篇) 在社会发展不断提速的今天,我们使用到开场白的机会越来越多,独具...
新春年会主持词
新春年会主持词范文(精选5篇) 主持词的写作要突出活动的主旨并贯穿始终。在当下的社会中,各种集会中...
老年人生日司仪主持词
老年人生日司仪主持词 主持词要把握好吸引观众、导入主题、创设情境等环节以吸引观众。我们眼下的社会,...
庆元旦主持词
精选庆元旦主持词3篇 主持人在台上表演的灵魂就表现在主持词中。在当下的中国社会,各种场合中活跃现场...
农村结婚典礼司仪主持词
农村结婚典礼司仪主持词(通用6篇) 主持词是主持人在台上表演的灵魂之所在。在人们越来越多的参与各种...
升学宴学生家长致辞
升学宴学生家长致辞 在日复一日的学习、工作或生活中,要用到致辞的地方还是很多的,致辞具有能伸能缩,...
家长道德讲堂主持词
家长道德讲堂主持词 道德讲堂就是一个引导人们讲道德,让人长好心的地方。崇德向善是我们中华民族的传统...
沙龙活动主持词
沙龙活动主持词(通用9篇) 主持词是各种演出活动和集会中主持人串联节目的串联词。在人们越来越多的参...
《纨绔》的经典台词
《纨绔》的经典台词 1、庸脂俗粉算得了什么?狐王才是真绝色。傻一时且说天作孽。傻一世便是自作孽了。...